
Initials of German verbs
I am learning German and amongst the things I do is keeping track of the verbs I master. I do it the old school way: on paper, alphabetically, one sheet per initial letter. It sounds crazy but it is really satisfying to see my verbs pile up and count them.
German builds some of its verbs via prefixes, which either add nuance to the original meaning or alter it completely. Those in the latter class are the hard ones to absorb, at least for me. Out of struggling to distinguish my aufmachen from my ausmachen, I started this exercise: at the very start, I made a list of all verbs I could think of whose meaning and usage I was sure of; now, I just add one every time I feel like I’ve learned it, as in, I’ve stored it in my (hopefully) long-term memory and I can comfortably use it.
The whole of German is wonderfully Lego-brickable, but I only do this for verbs because with no other part of speech have I had such struggles, and also because without a rock-solid foundation in verbs it’s hard you’ll be able to build coherent discourse.
I am between B1-B2 levels now and the below is what I’ve got. It doesn’t look like many, but there will be several (many?) verbs that I somewhat know but I’m not really sure about. Also, there may will be verbs I forgot to add. And, I am not tracking all possible easy combinations from a root (the first class from above): I haven’t added wegrennen (run away) for instance, despite understanding it very well and intuitively.
These days the adding-to-list frequency is quite low, maybe I’m approaching the stage where I need to level up and/or diversify sources to have a new burst of novelty like in the early glorious days of this.
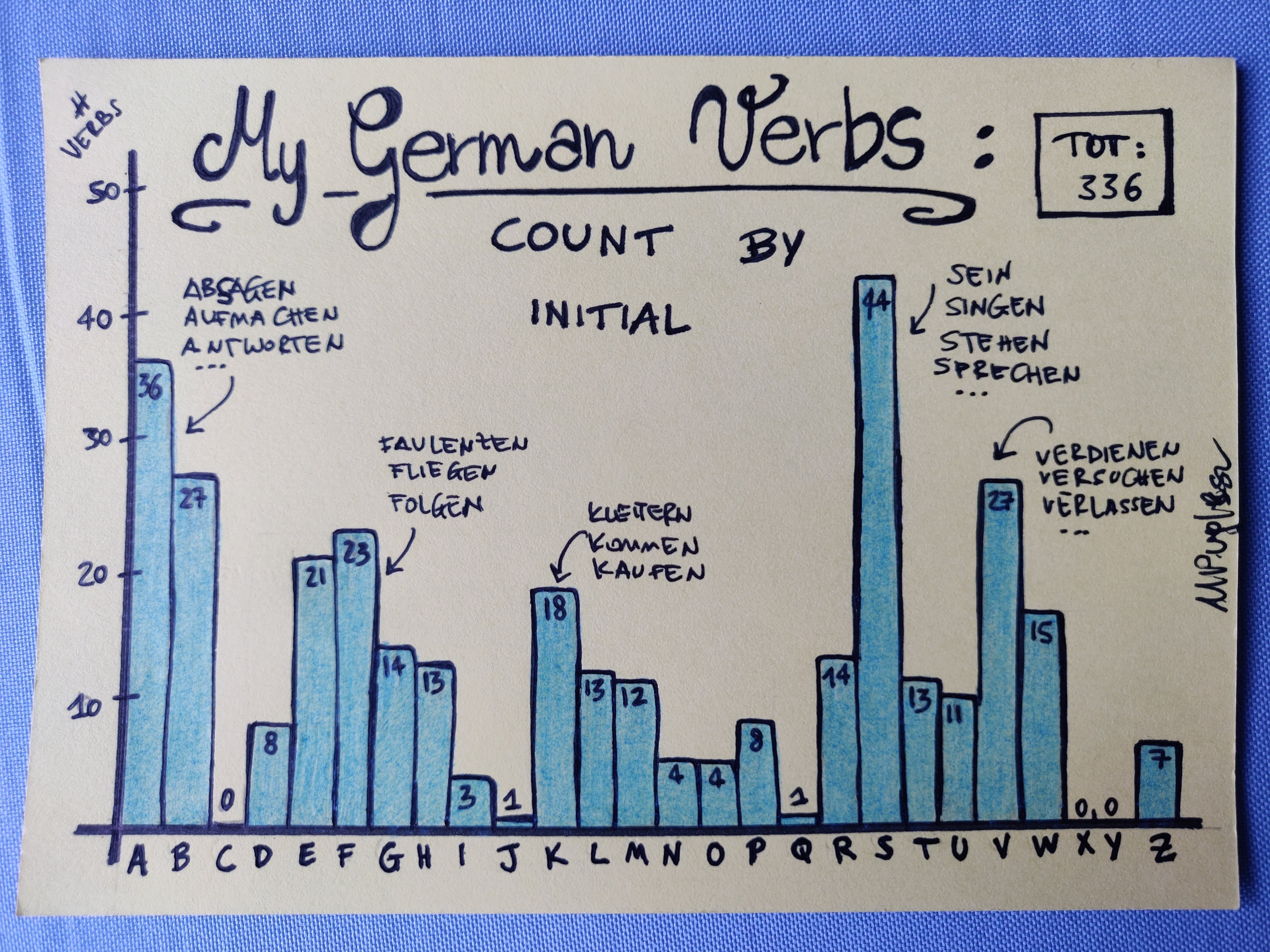
S really is queen! We have all the sein, singen, stattfinden, schencken, schicken, … There’s 0, nichts, for C - If I really think hard now, nothing more than an English loan like chatten, should it exists at all (not sure), comes to mind. X and Y have the same fate but that’s not surprising, most words there will be actual loans. Only 1 entry for J, that’s joggen, also a loan.
Likely, and this is important, my verbs are the most common ones (because I’m a learner and don’t yet consistently consume texts aimed at natives) so this isn’t necessarily representative of the whole vocabulary of German verbs.
Can I pull this data from actual German?
What if I want to compare my totally personal German verbs distribution with one derived from German general texts, not mostly those aimed at learners? There’s lots of sources I could use for this but I thought I’d query the mighty Wikipedia. Oh, how lucky, Python has a great package that lets you do just that easily-peasily. And spaCy has models trained for German (and many other languages), that I can use for POS-tagging (POS: part of speech) off the shelf. I don’t necessarily need much power so I’ve used the small model.
You can just do this:
import spacy
import wikipedia
# settings
wikipedia.set_lang("de") # set it to use Wikipedia German
lm = spacy.load('de_core_news_sm') # choose the spaCy language model
page = 'Deutschland' # title of a Wikipedia page
wikipedia.search(page) # this will give you best guesses at matching pages
# to get text content
dl = wikipedia.page(page)
# and to create a spaCy document
doc = lm(dl.content)
Initially I thought I’d pull content from some specific long and detailed pages, like the one about Germany itself (with all the history), some film ones, some about the brothers Grimm Märchen (fairytales) and so on. These are all pages rich in text and prone to contain narration, hence verbs. But the counts would be too few to be somewhat representative, and also the set would be biased by whatever set of topics I could think of. So I’ve added a bunch (many) random pages, which you can easily pull with this API:
wikipedia.random(pages=100) # a 100 random Wikipedia page titles
To extract verbs, following the spaCy POS glossary here and with the from above, I do
for token in doc:
# take all the verb POS tags
if token.pos_ in ['AUX', 'VERB', 'MD', 'VB',
'VBD', 'VBG', 'VBN', 'VBP', 'VBZ',
'VAFIN', 'VMFIN', 'VVFIN',
'VV']:
verbs.append(token.lemma_) # get the lemma, it'll be the infinitive of the verb
verbs = [v.lower() for v in verbs] # lower case as some will have a capitalised start
I’ve done a few rounds with random pages, considering that not all pages are rich in text (in fact, many are short, there’s also stubs, pages linking to others etc). After a while I ended up with
- content from 3712 pages
- which sums up to 2899268 tokens (words)
- of which I have 10351 unique verbs
That’s very different from my total 336 verbs. It’s been interesting to notice how the count of unique verbs grows quite slowly, it hadn’t saturated yet when I stopped (and it’s another question as to when it would do, maybe deserves another post) but it certainly decelerates. I end up with this (I’m not hand-drawing it this time):
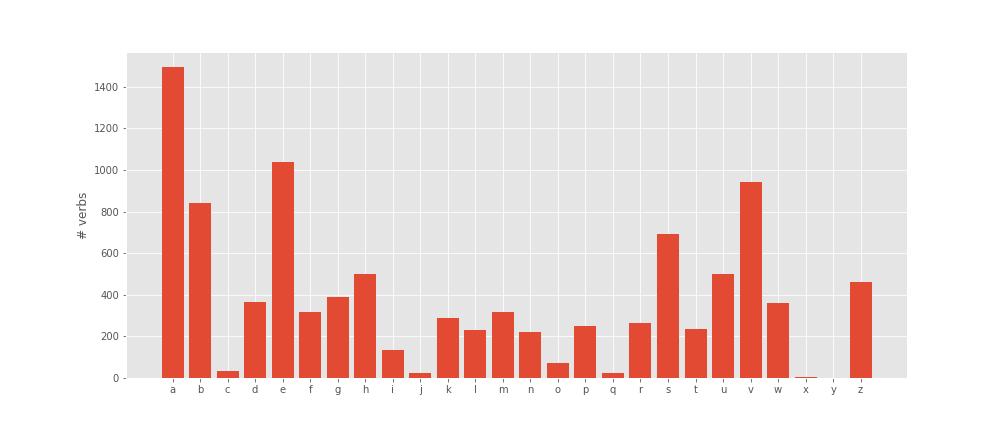
S is not dominating anymore although it’s still quite high, and in fact (this was unexpected for me), A is the top one! There’s a few prefixes starting with A so maybe that’s why, and maybe I haven’t encountered - or learned - those verbs yet. My K seems overinflated, maybe it’s the common verbs that are particularly concentrated there. For the rest, it’s arguably not that different.
As a note: spaCy does mistakes of course so there’s some things in there that aren’t verbs. When isolating the leading letters I also made sure to remove anything that wasn’t alphabetic, wasn’t a Latin character or was a punctuation sign, but some non-verbs still remain.
Well, this was a quite fun exercise and as I said I may dig some more, any comments please tell me here on Bluesky.
I also have a funky newsletter where I share these kind of things, you can check it out and subscribe here if you want.