
Using Claude to classify EU Cohesion Policy data
This post was prompted by work I’m doing about the EU Cohesion Policy data, focussing on projects for Italy: I’ll be using Claude (the Anthropic LLM) to classify strings of text into groups via its Python SDK.
I have open data about projects the European Union funds in Italy, retrievable from here either as CSV dumps or querying the API. I’ve downloaded the CSV for environmental projects in funding cycle 2014-2020, a total of 9134 rows. Projects under this theme include structural changes to water pipes for efficiency, seismic retrofitting, fire prevention and a bunch of other things. These projects are funded as part of the EU Cohesion Policy.
The data is complex and CSVs have many columns - I’m interested in classifying projects into themes/areas from their title only, mostly to use the data for analysis. Note that there are already several columns specifying a category/type for the project and referring to the sector, kind of infrastructure, source of funding so it’s not that I’m at a complete loss when it comes to that information - this exercise is however an attempt at seeing what Claude can do and whether I can obtain better data, as those columns are either incredibly detailed or not very informative for my purpose.
I used Claude Sonnet 3.5 which at the time of writing is, as per Anthropic’s own saying, “their most intelligent model”, and I’ll be querying its native API.
I did a few initial tests on the Claude UI to check feasibility with a small dataset (you can attach a file): it looked good so I’ve decided to systematise the job.
Some preliminary things, in terms of code (imports and setups):
import csv
import json
import pandas as pd
import os
from anthropic import Anthropic
from inspect import cleandoc
# define the Anthropic client
client = Anthropic(api_key=os.environ['ANTHROPIC_KEY'])
You do need to add some cash into the Anthropic workbench to buy prepaid credits and get an API key.
In order to pass CSV data to the Claude API, I’ve looked around the documentation but really the best resource was this video: you can just read the CSV data into a string and pass it as part of the user prompt. Because the data is in Italian I’ll keep the whole conversation in Italian.
After a bit of prompt engineering I’ve settled on this simple system prompt:
system_prompt = """Sei un esperto nella classificazione di stringhe di testo."""
which translates to “you’re an expert in text classification”.
A system prompt (not compulsory) is a way to “set the stage” and tell the AI how to behave or what “persona” to resemble.
Then I’ve used this user prompt:
prompt = f"""
Ti passo un CSV. I dati riguardano progetti di sviluppo territoriale a tema ambiente,
finanziati dal governo italiano, la colonna 'id' è un identificativo e la colonna 'titolo' il titolo del progetto.
Identifica l'ambito di ogni progetto dal suo titolo, classificandolo in gruppi:
esempi di ambito sono energia, spazi verdi, riqualificazione urbana, riduzione emissioni,
messa in sicurezza, dissesto idrogeologico etc.
Questo è il contenuto del CSV: <dataset>{DATASET}</dataset>.
Fornisci il risultato sotto forma di lista Python in cui ogni entrata è un dizionario con campi "id" e "ambito"
(usa sempre virgolette doppie) e non dire altro.
"""
where DATASET=df.to_string(), df being the dataframe read directly from the original CSV, where I’ve only considered the two columns of interest. The prompt is telling the AI that I’m going to pass it a CSV with two columns (identifier and title) and that the data is about government-funded projects for development of territories under the environment theme. As output, it asks to generate a Python list of dictionaries with the identifier and a generated category (“ambito”) as fields, and it gives some examples of possible categories (this isn’t in-context learning, it is just meant to give it a sense of what I expect).
It also asks not to say anything else - I’ve noticed the AI can easily generate more than just the dictionary otherwise (some preamble text, like “based on the data …”), which I don’t want.
Note that I need it to spit the identifier back in order to easily match the data after the fact and build a new column into the original dataframe.
This setup works well enough and it always produces out data in the desired format, e.g. this is a typical output (for 10 projects):
[{'id': '9CAPSRC_DI_C72', 'ambito': 'dissesto idrogeologico'},
{'id': '9CARIM-RSB', 'ambito': 'gestione rifiuti'},
{'id': '9UM5111399', 'ambito': 'mobilità sostenibile'},
{'id': '9UM5111412', 'ambito': 'spazi verdi'},
{'id': '9UM5111413', 'ambito': 'mobilità sostenibile'},
{'id': '9UM5111529', 'ambito': 'infrastrutture sportive'},
{'id': '9UM5111553', 'ambito': 'mobilità sostenibile'},
{'id': '9UM5111952', 'ambito': 'riqualificazione urbana'},
{'id': '9UM5111988', 'ambito': 'riqualificazione ambientale'},
{'id': '9UM5112737', 'ambito': 'valorizzazione territorio'}
]
Constraints
I need to batch the data in order to not risk exceeding the context window - we have 9134 projects whose titles together build up to 5M chars: of course this’ll exceed it, so I can’t possibly hope to pass the whole dataframe together. I could have of course classified one item at a time, but that felt like a wasteful process, given a large part of the prompt remains the same.
Now, the Anthropic tokeniser isn’t open, but there’s some ways you can get a feel of how many tokens your prompt consists of, using for example this tool. You can also use this open-source tool that examines API traffic to give an estimate (consumes tokens though!). Alternatively, see this thread for some ideas. Given I just want a very rough measure and I’d rather stay within context window boundaries and send more requests than risk that my context gets curtailed (losing input projects, which would mean having to identify the missing ones after the fact and sending specific requests for them), I keep it loose.
The main problem however is the max allowed tokens in output - at the time of writing 8192 for Sonnet 3.5: I need to make sure I get a response for all projects I input (again, if the token limit is exceeded the output gets curtailed, which likely means it won’t be valid JSON either).
There’s also rate limits and daily usage limits to deal with, and based on the tier you’re in (I’m on the lowest, Tier 1) usage and rates change.
With all this, I found that spacing the requests to around 250 projects each worked well for the majority of cases; towards the end of the list, I kept getting usage/rate limits errors so I had to batch in chunks of 60 and wait a bit between requests - the whole process did take some hours (and some supervision) to obtain all the desired data.
Here’s the the code for this:
i = 0
step = 250
while i < len(df):
print(i)
DATASET = df.iloc[i:i+step].to_string()
system_prompt = """Sei un esperto nella classificazione di stringhe di testo."""
prompt = f"""
Ti passo un CSV. I dati riguardano progetti di sviluppo territoriale a tema ambiente,
finanziati dal governo italiano, la colonna 'id' è un identificativo e la colonna 'titolo' il titolo del progetto.
Identifica l'ambito di ogni progetto dal suo titolo, classificandolo in gruppi:
esempi di ambito sono energia, spazi verdi, riqualificazione urbana, riduzione emissioni,
messa in sicurezza, dissesto idrogeologico etc.
Questo è il contenuto del CSV: <dataset>{DATASET}</dataset>.
Fornisci il risultato sotto forma di lista Python in cui ogni entrata è un dizionario con campi "id" e "ambito"
(usa sempre virgolette doppie) e non dire altro.
"""
response = client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=8100,
temperature=0, # keep it non-creative
system=cleandoc(system_prompt),
messages=[
{"role": "user", "content": cleandoc(prompt)},
]
)
d = json.loads(response.content[0].text)
json.dump(d, open(f'claude_resp_{i}_{i+step}.json', 'w'))
i += step
It’s not the cleanest of notebook but I’ve pushed all here. Note that it’s always a safer bet to cleandoc your prompts.
Cost
The whole thing ended up costing me $6. I made some mistakes here and there so I had to resend a bunch of requests (ouch!) and the cost was actually higher, but without errors that’s what it would have been, roughly.
Results
Overall, I got 9009 projects categorised: in one of the batch, 250-projects long, there were only 125 responses. I’m not sure why this happened and I’ve tried sending in those 125 missing ones again, but I received only 25 back. I suspect the reason here is that the model is not sure how to classify them and just decides to leave them out. From a superficial look, there isn’t anything particularly difficult or weird about their titles. Anyway, I decided ignore this issue, 125 over a total of more than 9000 isn’t too bad of a loss.
The number of unique categories generated by Claude is 706 and there are some repetitions (slightly different wording, same thing), like “accessibilità foreste”/”accessibilità forestale”, things like “non specificato” (unspecified) or very broad ones like “ambiente” (environment), but all in all I think this data is pretty good. The duplicates are easily reviewable/collapsable (and one could still ask Claude for that)!
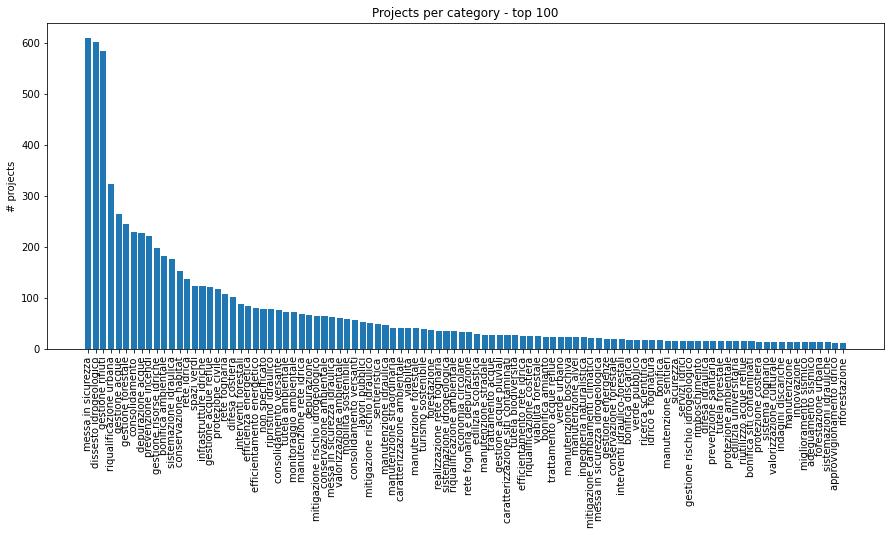
Now, in terms of quality, they seem good (I spot-checked a few). I didn’t do a detailed comparison with the existing description columns, but I’m quite convinced the Claude data is better to pick up the core of what projects are about.
Conclusions
I’m gonna use this data to create some visualisations from it. All in all, I’m pretty happy with my little $ investment, even though I didn’t get data for exactly all projects and some of the categories in output need a bit of post-processing. It was a good learning in terms of what to expect when send multiple items at a time, and the severity of current limitations of the tool.