
We made an AI agent
Creating AI agents is every techie’s favourite pastime these days, so my friend and I also made one. It aims at aiding the finding and consumption of scientific research and is aptly (we think, at least) called askademic. It works off of the arXiv API, so it can only really consider papers submitted to arXiv - unfortunately, and we’re aware, this leaves out a bunch of research in fields whose communities use other platforms to share research, but unless we’re wrong there’s no other freely available repository that’s also equipped with an API - if you know any, let us know! Of course, the other caveat is that arXiv is for preprints only, some stuff there hasn’t been peer-reviewed at all, it’s incomplete as some journals prohibit pre-publication, and so on. But again, it’s the best we (as society) have.
The amount of research appearing is on a clear upward trend and some fields are particularly popular, especially, and maybe unsurprisingly, Artificial Intelligence. It’s really hard, if not virtually impossible, to keep up with the pace, so we built something that could help us distill and easily find information.
What is it, what can it do
Askademic is a CLI tool - we’ve chosen to start with the path of least resistance, we may create a UI later on, maybe when the tool will have more features. It’s powered by PydanticAI as its agents framework and currently based on Gemini (2.0 Flash) as its underlying LLM, though we’re shipping support for other families too.
Askademic can:
- summarise recent papers (those from the latest available day) published in a arXiv category
- find specific information in the literature by answering questions
- talk about a given paper
All instructions are on GitHub but more details on what it can do and how are on the excellent DeepWiki (which IMHO is itself one of the best applications of LLMs).
The whole process of developing agents and orchestrating them is made very easy by PydanticAI, which has some rough edges being a juvenile project itself, but it is overall really good.
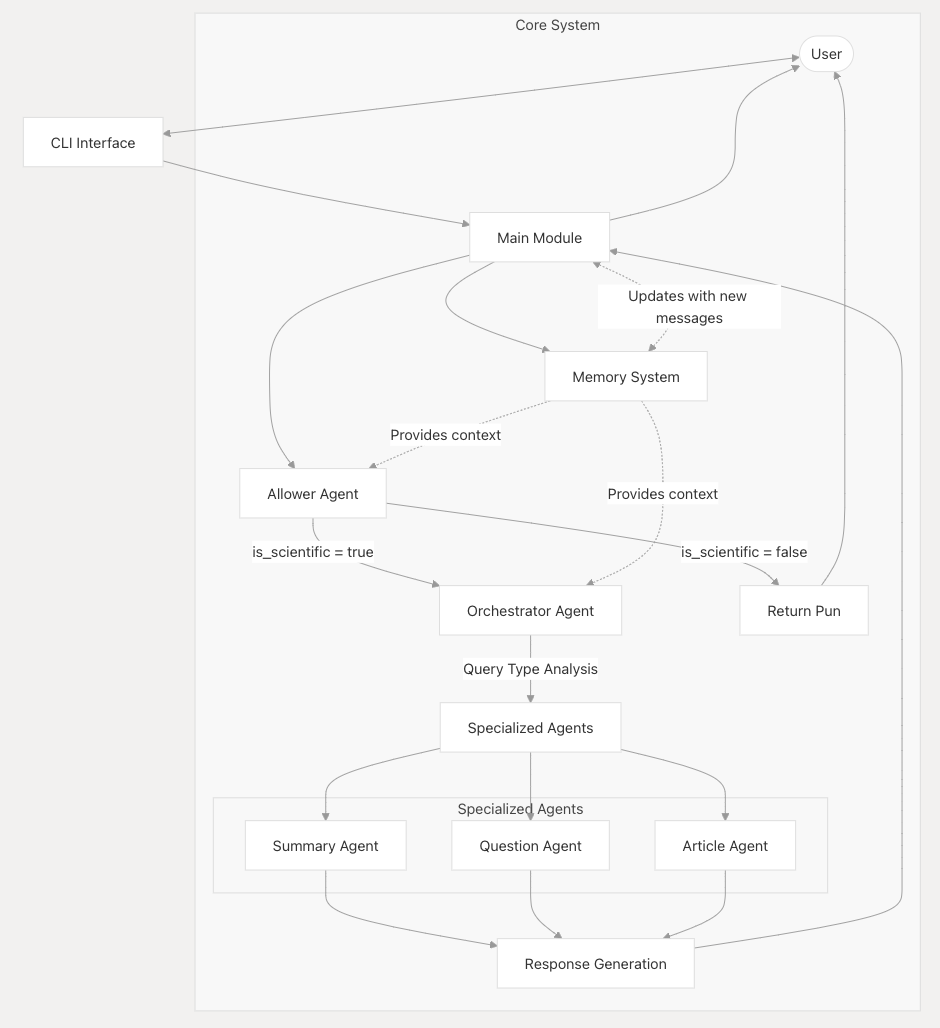
Science or pun
Your question first passes through an agent (“allower”) that decides whether you’re asking something scientific or not - in the latter case, it gives you a pun related to what you asked, e.g.:

Other things I’ve seen are
What is the capital of Italy?
I "Rome" around looking for science in this question, but it's just geography!
What is the meaning of life?
I'm not sure, but I bet it's not something you can find in a test tube!
… and so on.
Orchestrating
Passing this first layer there’s an “orchestrator” agent that triages the request to either of 3 sub-agents, depending on its nature: if you ask for summaries of recent papers by category it’ll go to a “summary” agent, a particular research questions will be given to a “question” agent, anything about a specific paper, given by title or URL go to an “article” agent.
The orchestrator has memory (message history), so to make use of what was discussed before in case you want to ask for follow-ups (which is particularly useful for the second use case, the questions one). The memory feature, courtesy of PydanticAI, works of course by attaching all previous messages exchanged to the prompt so that the LLM has context. This is where Gemini comes in handy with its 2M window context - it’s pretty hard to exceed it. We are adding support for Claude and one of the pain points is the limited (in comparison) context window - we are still experimenting with the best choices.
Summarising
Summarising works by using the taxonomy of arXiv categories and is based on abstracts. We feed the categories as hardcoded, each one is given as ID-description pair (e.g. “hep-ex” - “High Energy Physics - Experiment”). We were originally scraping the arXiv taxonomy page but that obviously proved to be the best way to get banned by arXiv (that is, to get given a captcha wall). Because there isn’t endpoint for categories, we resorted to just hard-coding the list.
The summary agent is instructed to:
- first, choose the most relevant category according to your request
- then, run a first API query to figure out what’s the most recent available day of publications
- finally, do another query for all abstracts of papers published in that category, which we then curtail to the ones belonging to the day from step 2.
We say all abstracts because we use a max of 300: this comes from a heuristic, the max we’ve seen published in a category in a day is below that mark so it seemed sensible, and a cap is useful not to explode the context too much anyway. Certainly a point of improvement. We use abstracts rather than full papers for the same reason, they’s add too much text.
You can e.g. ask
Give me the latest papers in group theory
and you get this kind of output:
category: category_id='math.GR' category_name='Group Theory'
latest_published_day: 2025-05-08
summary: The latest research covers several topics in group theory and related areas.
One paper focuses on proving a fixed point theorem for the action of $SL_n$ over local
fields on symmetric spaces of infinite dimension and finite rank
(http://arxiv.org/pdf/2505.05220v1). Another paper deals with the conjugate generation
of sporadic almost simple groups, determining a specific value related to their
automorphisms (http://arxiv.org/pdf/2505.05173v1). There is also a classification of
proper partial linear spaces affording imprimitive rank 3 automorphism groups,
including the construction of infinite families and individual examples
(http://arxiv.org/pdf/2505.05124v1). Further research characterizes nilpotent bicyclic
groups, generalizing a previous result related to abelian bicyclic groups
(http://arxiv.org/pdf/2505.05065v1). Finally, one article studies flag-transitive
automorphism groups of 2-designs with prime λ, identifying specific designs with
exceptional or sporadic simple groups as socles (http://arxiv.org/pdf/2505.04985v1).
recent_papers_url: https://arxiv.org/list/math.GR/new
Answering questions
This agent answers questions by looking in the literature. It’s made in such a way to:
- decide what queries to run agains the API, searching for matches within the abstract
- run said queries and collect abstracts
- evaluate all abstracts for relevance to the question and only pick the most relevant ones
- finally, read the papers related to those abstracts (but we curtail the number of them)
- produce an answer with all this info
For 1, it works pretty well because the arXiv API is based on Apache Lucene, the relevance retrieval is pretty good.
The paper retrieval is done by pulling from the site because the whole paper text isn’t reachable via API - this is something we need to improve to as again you may get locked out.
An example, with question How is the performance of LLMs measured when it comes to mathematical reasoning?
response: LLMs\' performance in mathematical reasoning is measured using various metrics and
benchmarks. Here\'s a breakdown of how the articles describe it:
* **Metrics**: The primary metrics used are Accuracy (ACC), Reasoning Score (RS), and Clarity Score
(CS), reflecting different dimensions of mathematical understanding and communication
(http://arxiv.org/pdf/2503.10573v2.pdf).
* **Benchmarks**: Several benchmark datasets are used to evaluate LLMs, including Math Competition
(MATH), Grade School Math (GSM8K), and Massive Multitask Language Understanding (MMLU) math subset
(http://arxiv.org/pdf/2503.10573v2.pdf).
* **Evaluation Framework**: A process-oriented framework is used to evaluate LLMs\' ability to
construct mathematical models, using solvers to compare outputs with ground truth
(http://arxiv.org/pdf/2405.13144v3.pdf).
* **MATHHAY Benchmark**: MATHHAY is an automated benchmark designed to assess the long-context
mathematical reasoning capabilities of LLMs. It includes questions of varying difficulty levels to
assess LLMs’ reasoning abilities across different input lengths (32K, 64K, 128K)
(http://arxiv.org/pdf/2410.04698v1.pdf).
article_list: ['http://arxiv.org/pdf/2503.10573v2.pdf', 'http://arxiv.org/pdf/2405.13144v3.pdf',
'http://arxiv.org/pdf/2410.04698v1.pdf']
Note that these are the API queries it ran (sorting parameters are not left for the LLM to choose, they’re imposed):
http://export.arxiv.org/api/query?search_query=abs:llm mathematical reasoning performance metrics&start=0&max_results=20&sortBy=relevance&sortOrder=descending
http://export.arxiv.org/api/query?search_query=abs:evaluating mathematical abilities of large language models&start=0&max_results=20&sortBy=relevance&sortOrder=descending
http://export.arxiv.org/api/query?search_query=abs:mathematical reasoning benchmarks for llms&start=0&max_results=20&sortBy=relevance&sortOrder=descending
http://export.arxiv.org/api/query?search_query=abs:llm performance on math problems&start=0&max_results=20&sortBy=relevance&sortOrder=descending
http://export.arxiv.org/api/query?search_query=abs:measuring mathematical understanding in llms&start=0&max_results=20&sortBy=relevance&sortOrder=descending
Talking about an article
This agent really is quite simple. It retrieves a paper by link or title, “reads it” as whole text (although we also curtail the input here, to a max of chars) and responds to whatever you asked.
For instance, asking what was the point of paper 'attention is all you need'?
will lead to something like
response: The point of the paper 'Attention is all you need' is to introduce a new and simple network architecture called the Transformer. This architecture relies solely on attention mechanisms,
dispensing with recurrence and convolutions entirely, to draw global dependencies between input and
output. The paper demonstrates that the Transformer is superior in quality, more parallelizable, and
requires less training time compared to complex recurrent or convolutional neural networks, achieving
state-of-the-art results on machine translation tasks.
article_title: Attention is all you need
article_link: http://arxiv.org/pdf/1706.03762v7
Reducing agency
Initially, each of the agent was doing all the steps on its own in a full pipeline. They had been conceived as single agents, with a detailed prompt giving all instructions at once.
We’ve now moved to a system where the summary and question agents are actually cascades of small agents each doing a step. Some of the steps may not be “agentic” at all, for example for the summary agent, there’s first an agent that chooses the matching category, then some other code runs the API queries (as opposed to an agent equipped with a tool doing thi), finally passing the results an agent that summarises the results. Similarly applies to the question agents, small agents in cascade “decide” what API queries to run, judge relevance of abstracts and then summarise the whole thing from the papers retrieved.
Why this? Because we realised that sometimes the pipeline as executed the whole way by a single macro-agent would go on forever, it would still run queries even when the answer/response was clearly there. We had to remove some agency!
This process is ongoing and we’re experimenting with the best compromises, also noting that there may be differences depending on what the LLM family is. For example, we’re currently in the process of reducing the agency of the “article” agent too, because when asked for a paper that doesn’t exist it tends to go on forever trying to find it. The old adage of do things the easiest and most reliable way, do not complicate your life adding uncertainty, still stands strong. Agents/LLMs are great for things that you can’t really do otherwise, things like searching for info within text or creating summaries or matching up content, but if they have too much to do at once the chances that they bomb it may not be worth the risk.
It is known that LLMs tend to be yes-minions, they’ve been trained to produce answers for a positive query (as in, when the answer exists) rather than for judging whether the query makes sense in the first place. We are learning about when it is best to leave them to decide things on their own and when a pipeline of intertwined agents/IFTTT statements suits our needs much better instead. This point will likely be explored in another post, hope you enjoyed this!