
Romance Languages, so near, so far
I always had a thing for linguistics, I even did a PhD where I studied the evolution of natural languages. It was in Physics but I dealt with Linguistics problems via the application numerical methods (that is, with data, measurements and calculations). The subfield goes under the name of “Physics of complex systems”. I’m just saying all this because it’s possible that in time you’ll see more stuff about languages here.
Anyway, here I wanted to find a quick and nice way to show how far apart Romance languages (the ones derived from Latin) are. Let’s see.
Bring-along items
As always, let’s set the stage with a few things that may give us context, or are just nice accompaniments.
Two movies
Most likely, the vast majority of movies you’ve watched is American. There’s a lot of stuff from other places though. I want to recommend two movies that I think are wonderful and whose original language is a Romance one. Both are coming-of-age tales, both with strong feelings of family and friendship.
È stata la mano di Dio (The Hand of God)
I may have recommended this already somewhere else (or will likely do). It’s a movie set in Naples (Italy) in the ’80s, and it’s just great. It’s in a mix of Italian and Neapolitan (which is what locals to the area use) and it tells the story of a young and passionate man, full of self-doubt and fear for the future. On Netflix.
La Famille Bélier
I caught this randomly a while ago, it’s a lovely French-Belgian movie (in French). I watched it in Italian though, as it came from the TV and Italy always dubs movies. There’s this farm girl that lives with her deaf parents and suddenly discovers to have a real talent for singing. Nice feel-good story, but it’s not silly, it’s really good.
A novel
Changing type of item, the crime novels by E. Mendoza are just awesome. Great plots, hilarious characters, great fun. When in Barcelona once, I bought “El laberinto de las aceitunas”, I then read it a few years later (so, in the original Spanish language) and it was a revelation, so I looked for other books in the series.
Mendoza’s prose is funny, the story is complex and full of twists, the main character is such that you can’t not feel empathy. Great reading, highly recommended.
The data card
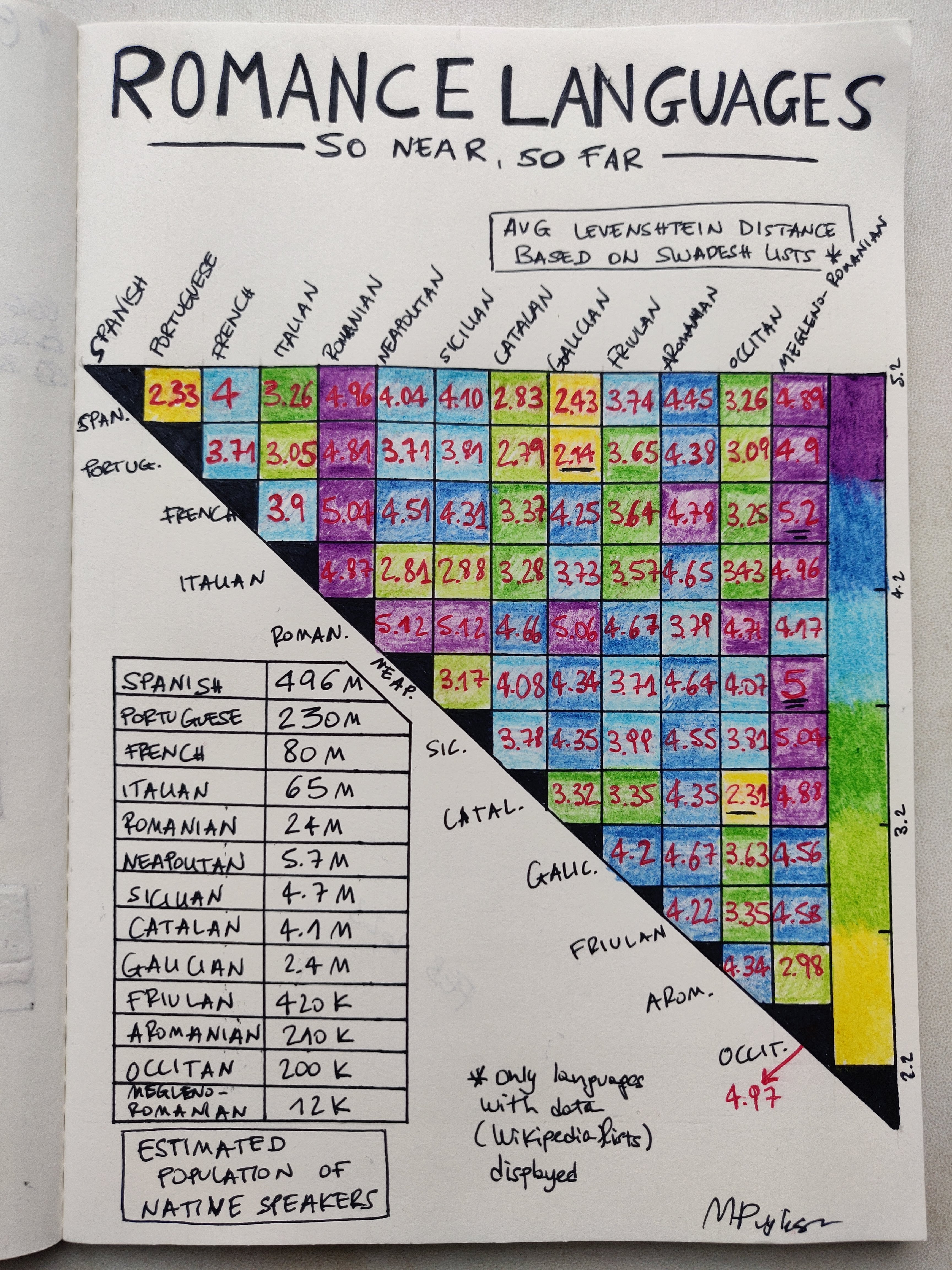
The card shows how far certain Romance languages are based on a concept of linguistic distance. Please note that the way I’ve calculated this distance is quite rough and serves for illustrative purposes only (see the technical section below for details). The heatmap is based on a colour scale, illustrated on the right hand-side, going from yellow (nearest couples) to purple (farthest couples). The distances are displayed, so that for instance Portuguese and Galician have a distance of 2.14 (and it’s the closest couple, which is understandable because Galicia sits right on top of Portugal).
There are many Romance languages spoken in the world and the ones represented on the card are those for which I could find the data I needed (again, the below section has details). On top of the major ones (Spanish, Portuguese, French, Italian, Romanian), we have:
- Neapolitan, Sicilian, Friulan: spoken in areas of Italy, often treated as “dialects” in common speech, but they’re not; these languages are “horizontally” related to Italian (that is, they are not derived from it but are rather on the same level)
- Catalan: the language of Catalunia (of course) and other areas of Spain, it is also recognised in parts of Sardinia
- Galician: spoken in Galicia (Spain) and neighbouring areas
- Occitan (also known as lenga d’òc): spoken mainly in Southern France
- Aromanian, Megleno-Romanian: languages of the Balkans and Southeastern Europe
I used this page on Wikipedia as a starting point to select the languages.
The card also reports the estimated number of native speakers of each language, again from Wikipedia: note that these estimates come from different sources and can be quite imprecise! The number of speakers matters in the evolution of a language: intuitively, a language with few speakers can be more stable and less open to contamination, one with many speakers is prone to have a certain variety within itself. Let’s also remind ourselves that Spanish, with its ~500M native speakers is one of the most used languages in the world.
You can see that there is a clear pattern whereby Eastern and Western Europe languages separate out, in terms of how far they are.
I should mention that I’ve done a mistake (visible on the card). I have not measured the triangle of the (half) heatmap very well and the error creeped up, so that I ended up accidentally filling in the space that should have displayed the distance between Occitan and Megleno-Romanian. This is the reason why I called that out in red outside the map.
The technical work
To fully understand the numbers shown on the card, we have to pass through some basic linguistics.
Selecting languages
There’s about 7000 living languages in the world, which is why I decided to focus on the family of Romance (also known as Neo-Latin) ones. Taking even just the Indo-European families would have been too many for a visualisation like this.
There’s a tool in classical linguistics that is used to measure the lexical diversity of languages: the Swadesh list. Swadesh, a linguist, in the 1950s created a list of universal concepts for use in comparative linguistics: you take the words to express those concepts in every language use them to compare how languages differ from the lexical point of view. Of course, a language is more than a collection of words, and there’s more than a comparison of letters to languages distances (there’s meaning, for instance). But this is a classical tool meant just to give a purely lexical measurement.
The original Swadesh list contained 215 concepts, but it has since received several edits, landing in the most recent version of 207 concepts. Concepts encompass personal pronouns, parts of the human body, verbs for basic actions, size and shape nouns and so on - here’s the list for English.
I’ve used Wikipedia to gather data about the number of native speakers of each Romance language (these are the numbers shown in the bar plot) and to select those with Swadesh lists, as not all do (at least on Wikipedia). This is how I ended up with the 13 languages shown in the card.
Calculating language distances
A big caveat: this is the part which from the linguistics point of view is very rough - I have used a rudimentary method to calculate distances between languages, the real way linguists use is much more sophisticated and takes into account dimensions like semantics as well (as hinted above). However, this simple way gives us a decent starting heuristics, an idea.
The Levenshtein distance between words w1 and w2 calculates how many changes it would take to go from one to the other in terms of character edits, insertions and deletions. For instance, the Levenshtein distance between “air” and “airy” is 1, because you only need to add a character, between “far” and “fairy” is 2, because you need to insert two characters.
So what I’ve done for the distance between two languages has been:
calculating all Levenshtein distances between the Swadesh words for the same concept in the two languages, for each concept
average all these distances between concepts to have the overall distance between the two languages
For instance, for the distance between Spanish and Italian, I had these Swadesh list (English words, Italian words and Spanish words reported, concept by concept):
| English word | Italian work | Spanish word |
|---|---|---|
| I | io | yo |
| you | tu | tú |
| … | ||
| this | questo | ese |
| … | ||
| grass | erba | hierba |
| … | ||
| knee | ginocchio | rodilla |
| … |
I calculated the distance between “io” and “yo”, “tu” and “tú”, “questo” and “ese” and so on. Then I averaged all these numbers to obtain the (average) Italian-Spanish distance.
The card shows these numbers and creates a heatmap colour scale.
Oh, I have a newsletter (see link in navigation above), if you want to get things like this and more in your inbox you can subscribe from here, entering your email. It’s free.