
Don’t make recipes out of them
Machine Learning is not a set of pre-cooked supermarket meals
Machine Learning is a very popular topic in educated small talk these days, partly due to the relatively recent surge in “Data Scientist” positions around and partly because as humans we typically get fascinated by something, we think it’s appealing for a certain period of time and then our excitement fades away, freeing our mind to focus on the next big thing. Artificial Intelligence makes a good example. We are currently observing gigantic improvements in the capabilities of machines in terms of problem-solving abilities and research in the field is experiencing a new youth after the idiosyncratic history it has gone through in the last 60 years, as outlined in this excellent Medium post. We talk a lot about it, we love mentioning “Deep Learning” whenever the occasion seems favourable, but eventually the ones who do cutting-edge research in this fields are the same people who were already doing it before we even noticed. Or cared.
Never stop learning, but go straight to the core
Machine Learning has traditionally lived at the border of Computer Science and Statistics: the former provides the computer implementation, the latter provides the bulk of the model. Of course, overlap means that people from different backgrounds not only collaborate on a task by splitting the work but also exchange ideas and points of view, ultimately doing a bit of the work of the counterpart as well.
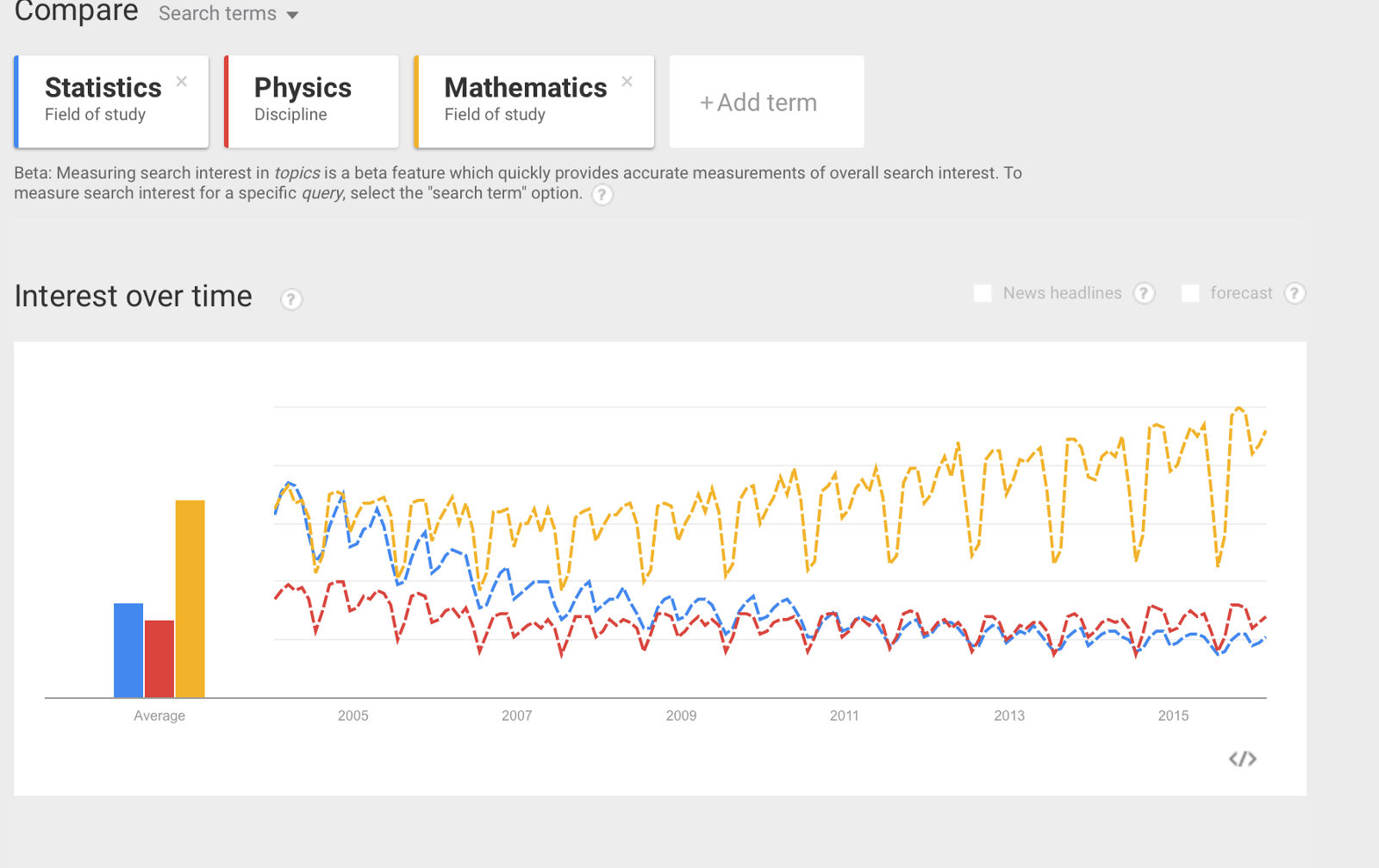
Statisticians today find themselves in a very interesting situation as they are seeing the things they’ve been using for decades advertised as something “new” and “cool” all over the place. Until probably about 5–6 years ago not many people would have talked of their tools as something particularly enticing. They must be a little bamboozled. The idea behind Linear regression is extremely old, dating back from more than a century; the standard algorithm for a k-means clustering was published in 1957; ID3 for decision trees is around 30 years old; Naive Bayes classifiers, beyond being based on a theorem of the eighteenth century, were developed throughout the fifites. I could continue but this should give the idea. This stuff is not new. Physicists have been dealing with the problem of regression ever since, usually calling it fit. When you have experimental data points and a hypothesis to study, you fit the points to it and compute how good your fit is. In a typical situation, a statistician’s dataset is noisier than that of a physicist as it may not have benefitted from the luxury of an experimentally controlled framework. Hence the amount of noise may be high. The statistician’s job is exactly that of figuring out a pattern out of the (noisy) data. The pattern can then be used to do predictions. Of course research in these topics is always ongoing and everyday sees improvements, tweaks, suggestions to better validate old algorithms’ accuracies. So nothing here is dead. There are papers who propose new ideas over old and robust stuff. What happened then? Why is it that lots of people mention these things only now, sometimes talking in words and without discussing the concepts? It’s an effect of the boom of Data Science around. Data Science is a glorious field, and it truly lives at the intersection of several traditional disciplines. Furthermore, when carried out in the industry, it encompasses non-academic skills like business acumen. Its rapid growth is due to the ubiquitous presence of data to be crunched, but several of its core methods are not new. I’m very happy if this new state-of-the-art situation can help mathematicians, physicists and statisticians ameliorate their reputation among the general public, relieving them from having to cope with being considered uninteresting and sometimes pathologically isolated. But this is not about emotions. It is about science. Don’t make a kitchen recipe out of an algorithm. I love cooking and I know that when you cook there are some “rules” to follow in creating a delicious dish. You can exercise your creativity and break the rules a tiny bit, by switching an ingredient with something else, adding something a little unconventional or removing the ingredient you don’t particularly fancy there. Ultimately you will have created a new version of the dish, which will be prone to criticism from both the conservative-minded (in cooking terms) and from the more “avant-garde” enthusiasts. Nevertheless, when cooking a well-known dish, you’re going to follow some rules, which are either written down by someone in a recipe or are in your head for your personal interpretation of that dish.
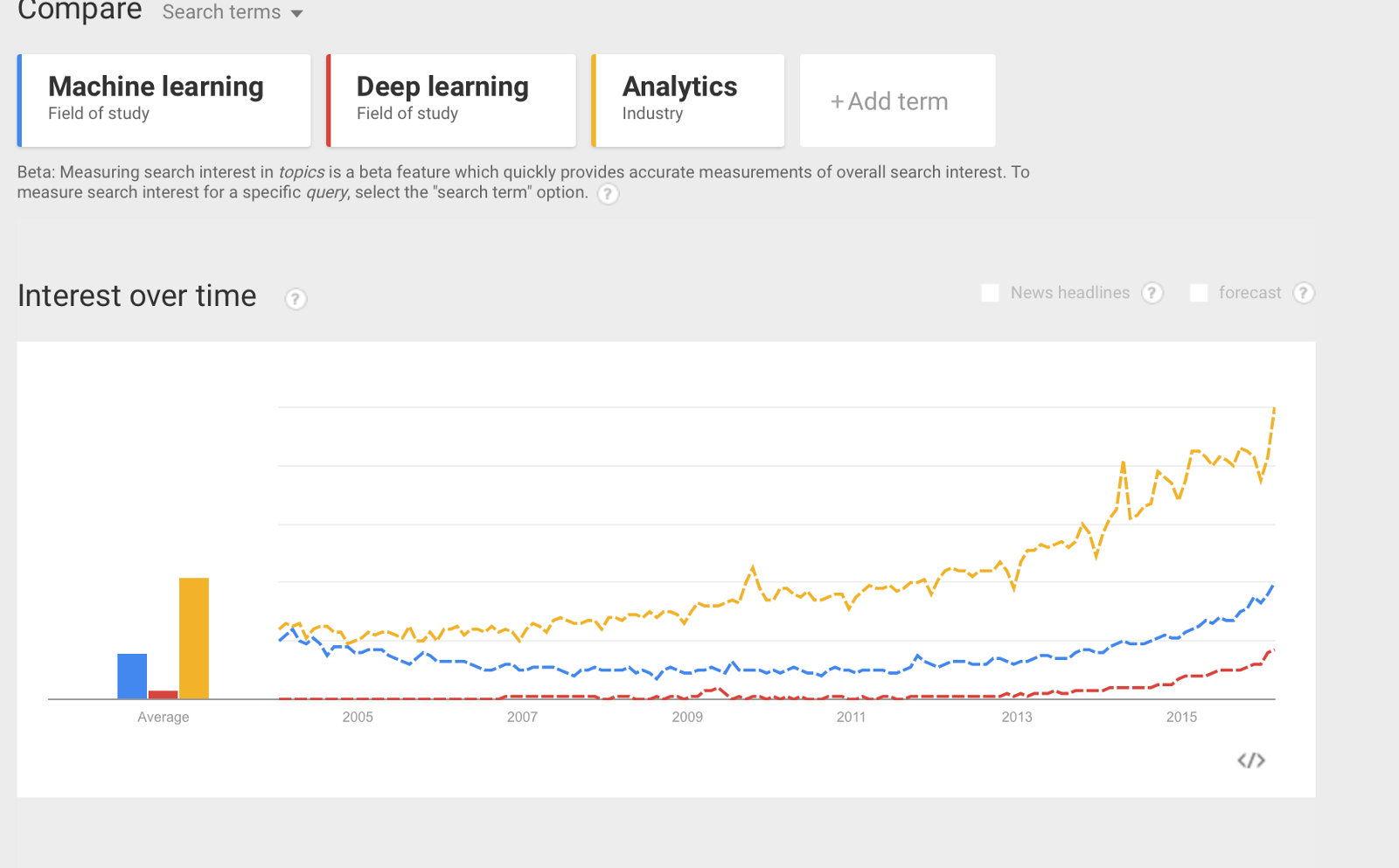
Google Trends on some of the essential building blocks of Data Science. Interestingly Mathematics exhibits a slowly increasing envelope. Statistics seems to be decreasing in interest: essential as it is, should be receiving lots of love.
Machine Learning is not cooking though. Sure, there are established and robust techniques, and you certainly don’t want to reivent the wheel when solving your data problem, but don’t treat them as a set of fixed rules to be applied for the goal. The core word in Data Science is science (and this one here has lately become by favourite quote), hence when you solve a data problem you are expected to approach it scientifically. This does not involve blindly applying an existing black-box without a thought process beforehand. We use libraries to perform tasks because they save us time. We tale advantage of the work of someone else who coded the tools in a clean and robust format. Writing the algorithm code again would be pointless. But we want to make sure we are understanding what we are using, why we chose that specific box, how we can choose its parameters and finally how good it is for our needs. And we need to be able to replicate what we are doing on paper. Often, the feature extraction phase requires us to come up with metrics which aren’t there anywhere, because they would be specific to our problem, and to the data we have to tackle it. This is were we get scientifically creative. Then we use the algorithm. Data Science is not about running that specific code coding for that “thing”, it is all in the journey from raw data to information. It’s all in the journey you build.