
Cheers to PyData Edinburgh for its first birthday
Back in December 2017, a few of us based in Edinburgh and rotating around the data community here got together around the idea of opening up a chapter of PyData in the city. The data science/engineering community in Edinburgh, and in Scotland as a whole, isn’t huge and in many respects it still quite at its early stages; we were all interested in doing something for it (and for ourselves really), something to foster more dialogue around the field, with an accent on the technical side. At that time, there were already a few meetups and events related to data science, more focussed on the business side of it than on the technical one though. In fact, Scotland is a great place for tech in general and data science in particular, but it was missing a piece: an event to talk data science in practice and learn together.
There were a few ideas on how to do this, I was one of the proponents of doing a sort of all-hands round table every month with the about 20 people I could count as working in the field. The idea was simple: coming up with a topic to talk about every time and discuss it openly, sharing code, papers and so on. Not a very structured thing really, and could have worked on a small group, certainly not when you reach certain volumes.
Other people were thinking bigger already and thought that despite the community seemed so small, times were mature to start a PyData chapter. And so we did. And it was the right thing to do! PyData is an international community supported by many people and it’s awesome.
We just hit the first birthday milestone this February and it’s been an amazing year in terms of participation, quality of the events overall, traction we have seen. We have sponsors that support us and the group is quite established and known around these days. We have done 11 events so far (missed March 2018 due to snow and August 2018 because we had done a special one the month before on the back of EuroPython being in Edinburgh).
At the moment, there are four of us in the org team: Nick (chair), Sam, Thomas and me. Matt has helped us in the starting stages as well. My thanks goes to all of you.
When we set up the first event, we weren’t sure how many people would be interested. Opened the page on meetup.com, set up everything, we had a great first speaker and decided to try the format of one main talk + a few lightning ones. 100 people was the limit we put as maximum allowed, 100 people signed up and I think that night actually more showed up (me and Matt lost count while manning the door). Huge success, great time. Since then, every event has hosted between 85 and 95 people, so largely consistent. We honestly didn’t expect this.
At this very the moment, there’s 804 members of the meetup group (signed up on the page), which is really not bad for a city of 482k inhabitants. Of course, signing up on a meetup page doesn’t necessarily mean much more than expressing a certain interest in the group and is not a commitment to actual participation. However, good interest.
In Europe, the largest PyData group is London, which is also the european Data Science hub. If you consider the UK alone and fetch those groups which are comparable both in terms of size of the city and number of overall members, you have Edinburgh, Bristol, Cardiff and Manchester. The data is available about signups in time, so you can calculate a growth rate in time for those groups (see figure).
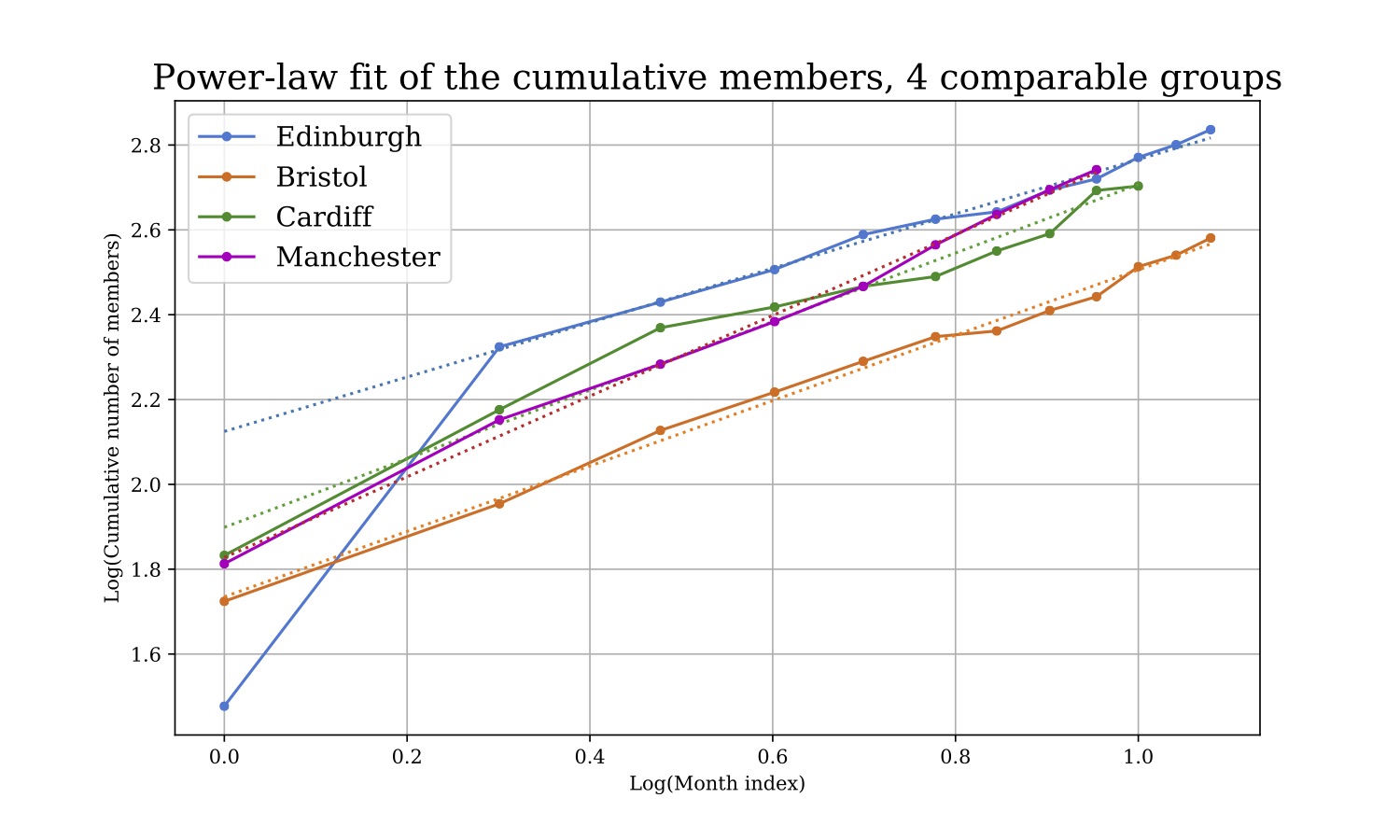
The plot shows the cumulative monthly numbers of members for these groups in time, using a log-log axis which aids for fitting the curve. The curves have been shifted to have the same starting point (as it’s not important in which month they started). Note that for Edinburgh we’ve seen a huge jump in memberships after the first month as the group was opened in December 2017 and the first event run in January 2018. Anyway, the fits are relatively good, and slopes come at 0.64 (Edinburgh), 0.77 (Bristol), 0.81 (Cardiff) and 0.95 (Manchester). Note that the data is up-to-date to November 2018. So it seems we’ve been actually growing slower than our comparable groups! No hard feelings.
Another, possibly more interesting thing you may ask yourself is what’s retention. The more time went by, the more familiar faces we’ve been seeing around at the events, so it was clear some people kept coming by. Which is great, what better proof something is appreciated than when people come back organically? The events are monthly so to measure retention what you can try doing is seeing how many people show up at how many events. This is what the figure below displays.
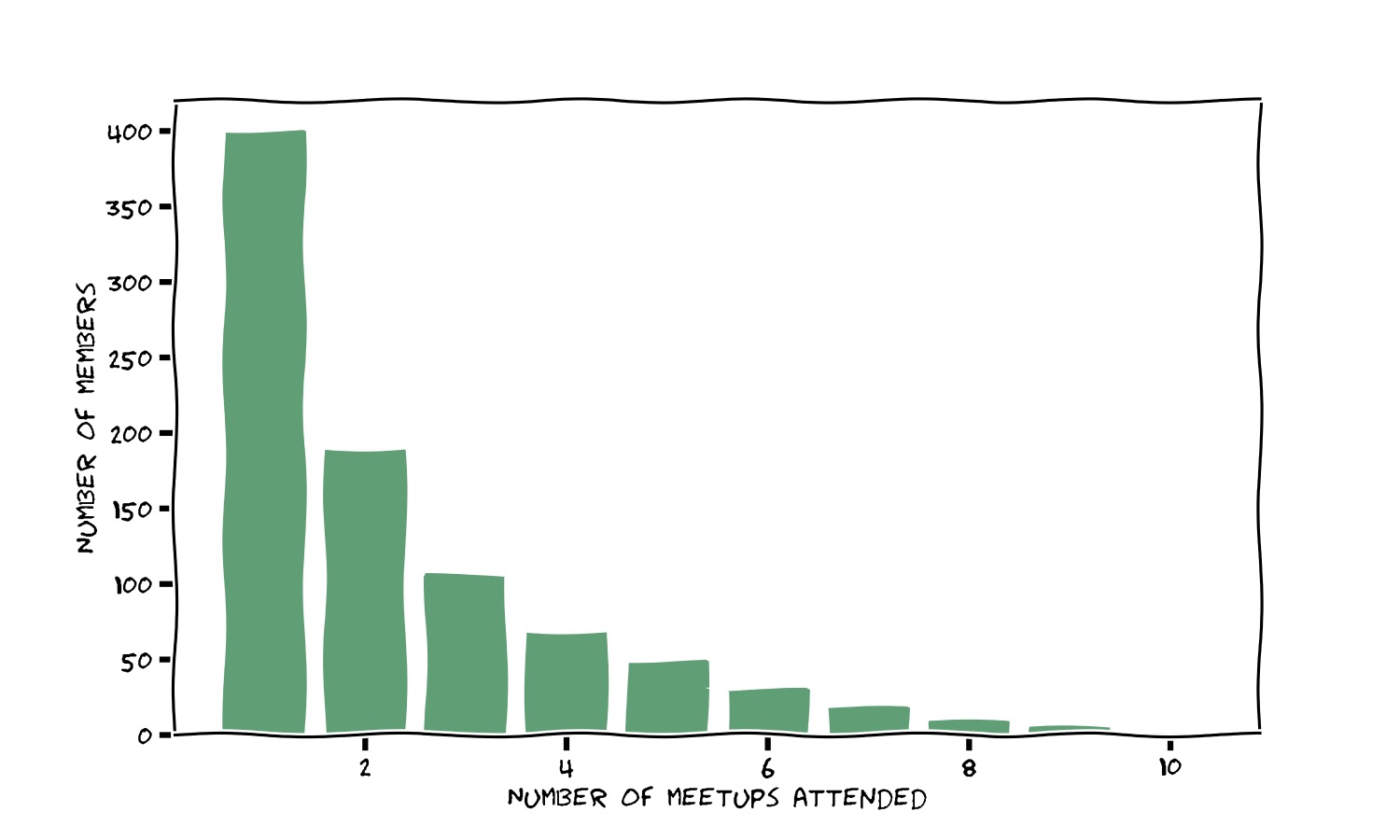
About 400 people (out of the 800 total members, so half) came to at least 1 event, about 200 came to at least 2, and so on going down. This plot was realised exactly before the birthday event, when we had done a total of 10 events, and it was fun to notice that no member had attended all 10 events, not even the organisers (yes, I missed two so far!).
Another little thing you can do is, for a 2 events retention, fetch all the possible couples of two meetups and see what is, across them, the average number of people who have attended both. It is 25.8. For all possible triplets, the average number of people who attended all three is 12.5. For all possible combinations of four events, it is 7.2.
To recap, and numbers aside, we’re quite happy to have opened up something that seems to generate a good participation in the community here, yield good chats, possibly some collaborations and all in all give all a good night. The audience is a mix of data scientists, students, educators, professionals in other fields. It’s great to have a place to meet around and share knowledge.